题语:世界杯开始了,大家又重燃了看球的热情。对于游戏制作来说,经常需要制定一些角色的数据,特别是体育类的游戏。自己去设定工作量大,并且太主观,这时候就需要去一些权威的网站查询数据,,用作参考。笔者结合自己实际经验,教大家做一个简单的爬虫。
前期准备工作
首先确定我们需要爬取的是FIFA23的球员数据,通过https://sofifa.com/ 这个网站,里面有从FIFA07到FIFA23所有的球员数据,非常详实。打开首页后,发现是这样的:
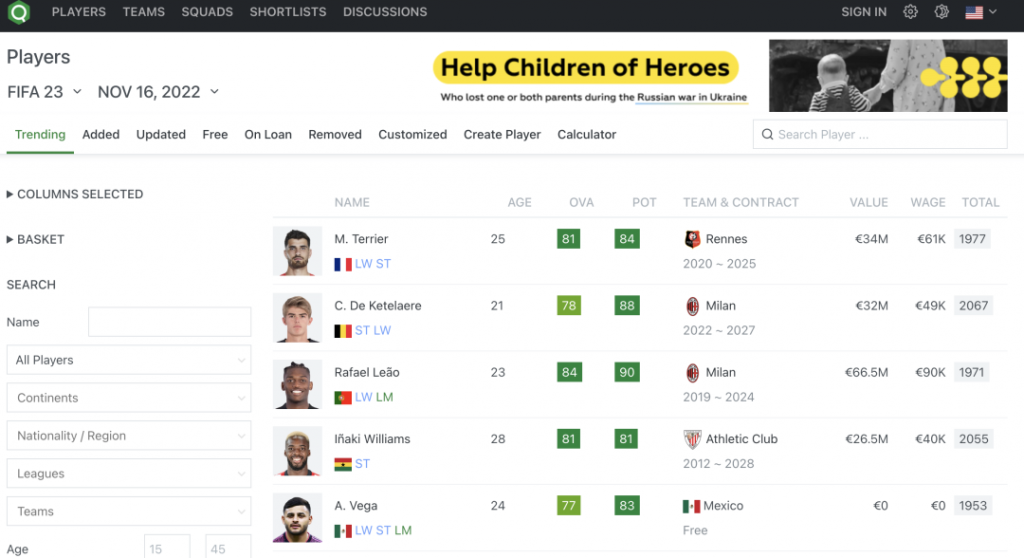
我们点选其中一个球员,进行分析:
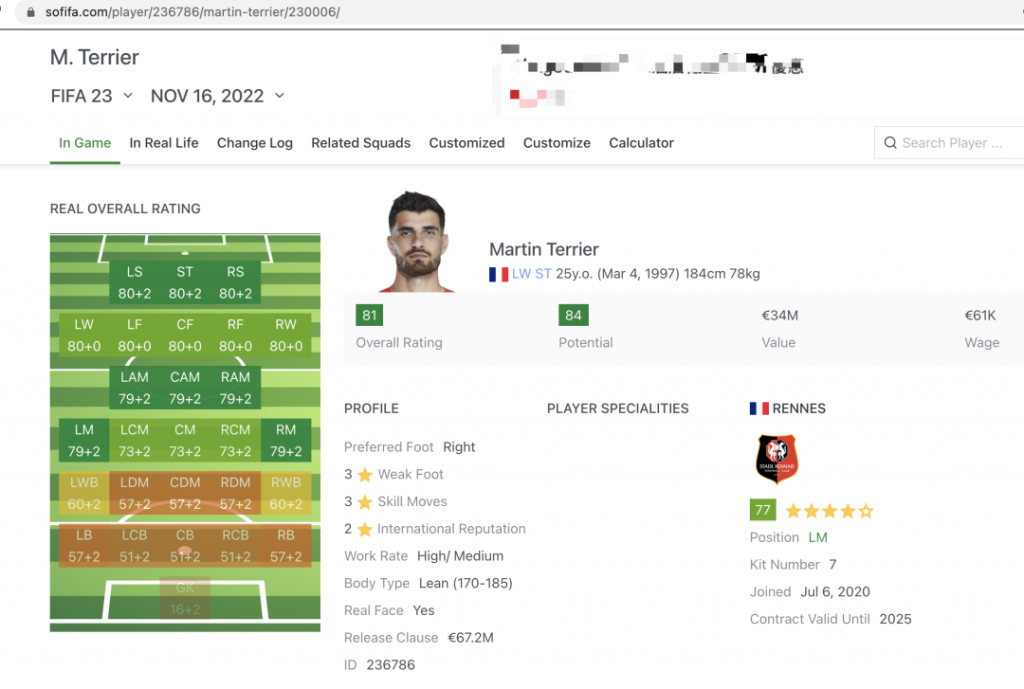

发现所需要的数据,都在上面俩张图的位置中。下方是转会记录和用户评论,现在用不上。
经过分析发现,每个球员都有一个唯一id,显示在网址url中。无论是通过姓名搜索,还是通过球队搜索后跳转,球员的页面都会显示这个id。
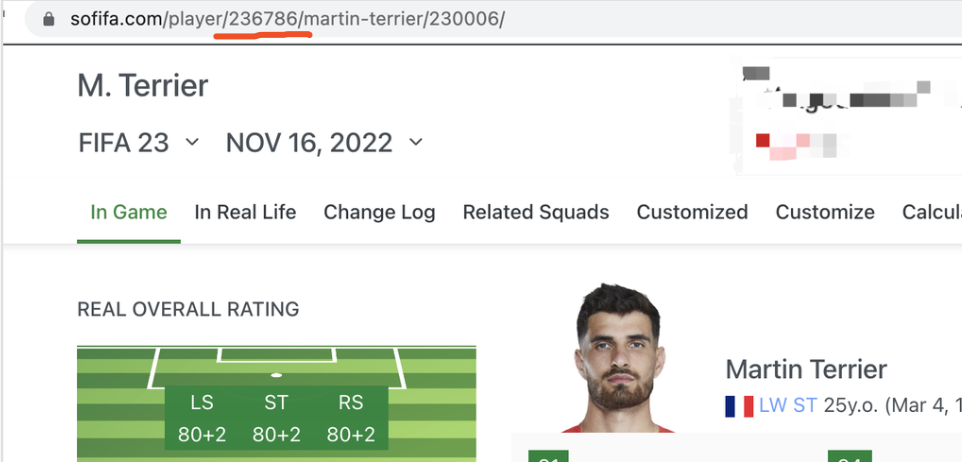
最后的230006这串数字,应该是某种参数。在url去掉后,依然会打开该球员页面。
去掉球员名字后,依然可以打开页面。

所以我们明白了—-所有人的只是一段数字。
到这里,前期的重要准备已经完成了。我们发现了规律,下一步需要去运用了。
开始动手
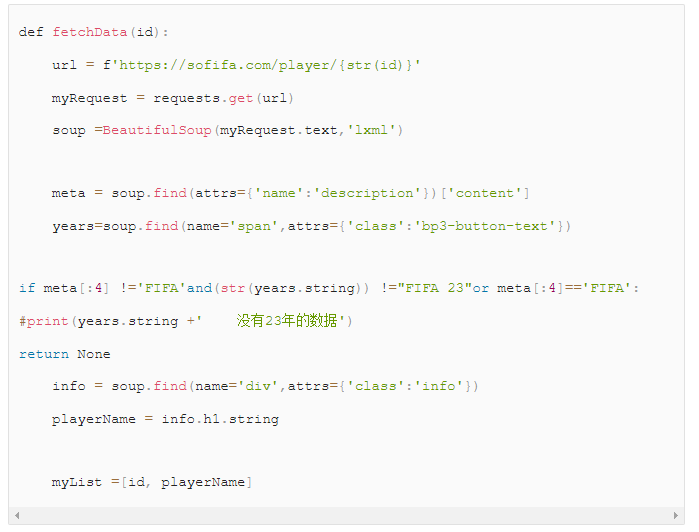
安装python,笔者使用的是3.9.12版本。然后安装requests库和beautiful soup库,可以使用 pip install requests,pip install beautifulsoup4来安装,或者用conda来管理安装包、关于如何安装请自行搜索,不再赘述。先写用来获取球员数据的最主要的函数:

我们通过id来获取一个球员的信息,所以参数是id。只要递增id就可以来爬取所有球员的信息了。如果查无此人,就返回一个空值。注意request如果返回的值是200,则表示连接成功,至于重试和http header怎么设置,请自行搜索。
页面上取值
按F12查看页面元素,取到所需的值。每个项目都不同,下面的展示是我们所需要的。
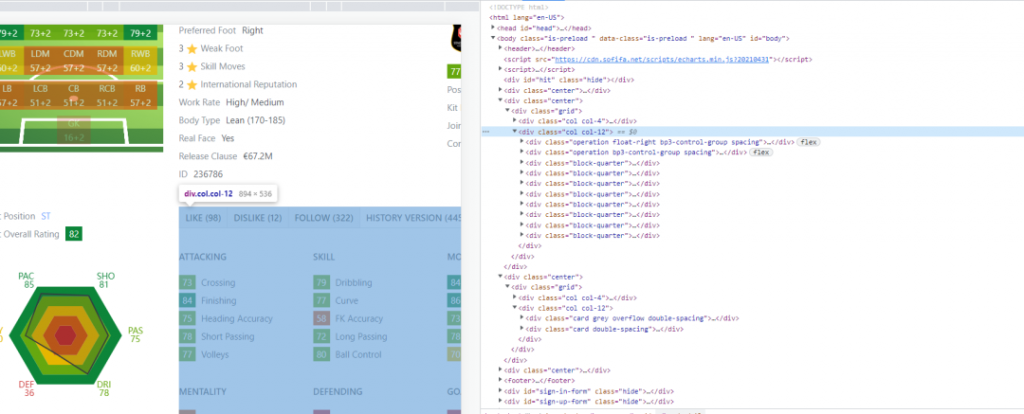
meta数据
有一段页面没有显示的meta数据,里面记录了该球员的描述。我把这个得下来,用来跟同名的球员快速对比。
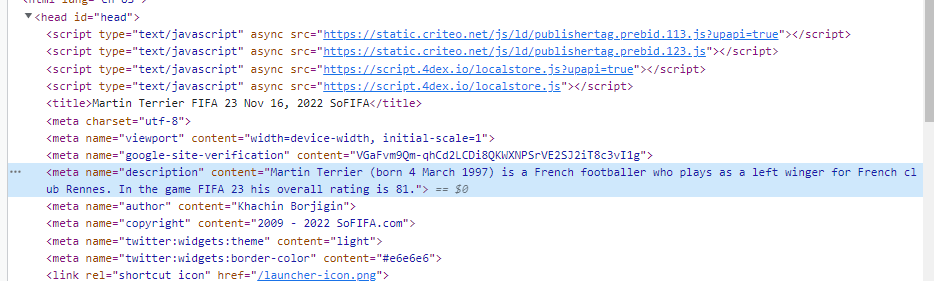
过滤年份
因为要取最新的FIFA23的数据,所以我过滤了左上角的年份,不是23年的就会返回空值。
到目前位置的代码:
基础信息
获取位置\生日\身高\体重等信息,我们可以看出来,这是一个字符串。

这里用到了全篇都在用的,省脑子的做法,就是改变selector。右键选中需要爬取的部分,选择copy selector就可以复制到剪贴板上了。
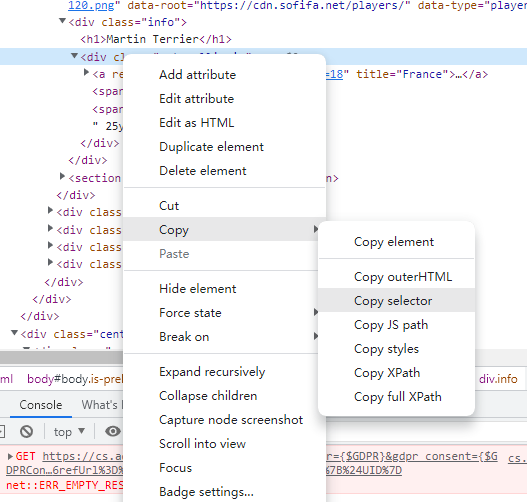

FYI:也可以使用XPath来选取,不过需要稍微学习下XPath的语法。Chrome有一个XPath Helper插件可以很方便测试XPath的语法写的对不对。
因为球员可能会有多个位置,最多的人我见过有4个位置的。所以下面代码中我做了一个偏移,这样保证截取的字符串部分是对的。

生日信息并转换
获取生日信息,并且转换成我们所需要的格式。这里提一下,“日/月/年”的格式被excel打开后会自动转换成日期格式,麻烦的要死。我的做法是:要么用wps,要么用飞书打开,再粘贴回去。如果大家有更好的办法欢迎留言。下面是身高体重,很简单的截取字符串。

获取Profile
我们需要获得页面左边的Profile信息,包括正逆足,技巧动作等级,进攻防守参与度等等。

左脚定义为1,右脚定义为2,这种魔数(Magic Number)在项目中大量存在… 只能微笑面对 🙂

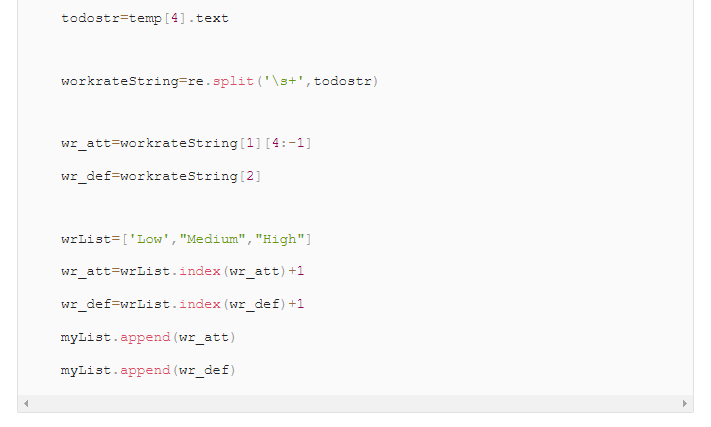
可以看出来,最多的代码就是用来拆分\拼接字符串而已。
头像
下面要获取头像了,各类图片都差不多的处理方式,可以说是爬虫里面最有用的部分了(误)。头像要获取img的url地址,然后用stream的方式进行下载。这里最需要注意的是图片命名,别down下来之后自己分不清楚,confused了。(这段话打着打着就出现了中英混杂,但img=”图片”,url=”地址”,stream=”流”,替代之后就会发现很别扭,求大家指导一下,怎么用纯中文打出文化非常自信的代码教程。)

题外话:很多网页上的图片下载回来发现是WebP格式,也就是谷歌搞得一个格式。大家可以下载”Save Image as Type”插件,右键可以另存为PNG或JPG。
其他信息:
其他位置信息,俱乐部信息,和国籍信息,都使用了一样的办法—-哪里不会点哪里,右键复制个selector就完事。

属性
重头戏来了,这七八十条属性,是手动抄起来最麻烦的,所以才写的这个爬虫。

分析发现每个属性的值也写在了类的名字里,例如这个 “class=bp3-tag p p-73″,共性就是”bp3-tag p”的部分,所以需要用到了正则表达式(其实上面也用到了,re就是正则,我认为你们不懂的会自己去搜索,就没多说)
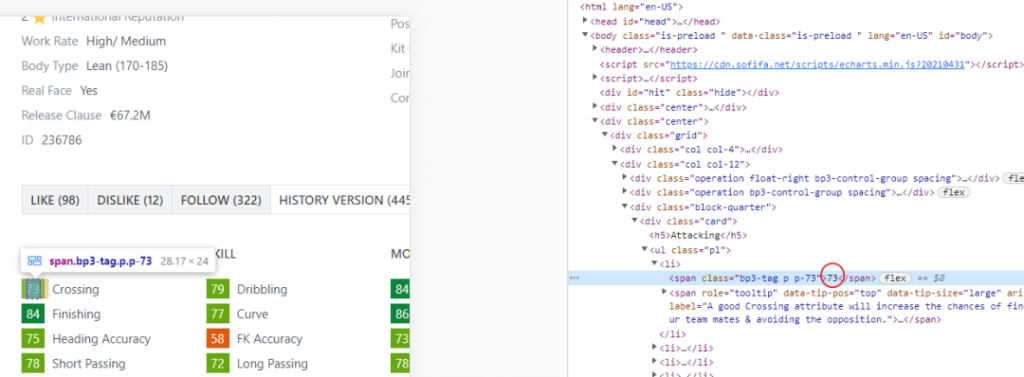
就酱,最后把属性作为一个列表返回去,爬虫主体函数就完成了。
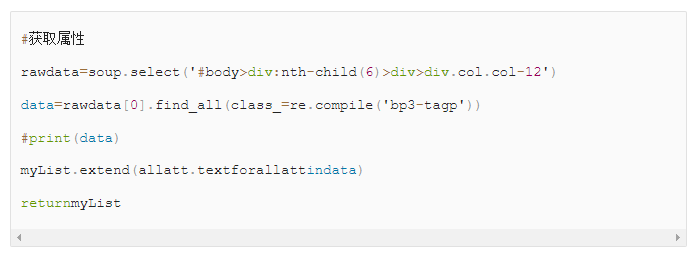
写入文件
在开始下一步前,先把写入的函数做好。不然好不容易爬到的数据,只在内存里,很容易就丢失了。很多非程序员可能不了解,这个过程就叫做”持久化”。正所谓,”不以长短论高下,只凭持久闯天下”,说的就是代码。推荐写入使用csv,其他格式也一样,如果要写excel,推荐使用openpyxl库,以下时代码部分,最长的那里是表格的头。

另外关于写入的几种模式:w,a和+的用法,请自行搜索(写教程好容易啊)。
搜索id
如何调用上面的函数?需要的球员id从哪里来?这里我用到了2种方法,分别介绍一下:
递增ID
最早用了递增的id进行遍历,属于广撒网,多敛鱼的方式。这个方式就很坑,通过这个搜索到了很多网站页面不会显示的球员数据,例如女足球员的数据。

这样如果搜一条写入一条,效率是非常差的,可以分批次来搜索,比如一次100条,然后整体写入。写入CSV时可以把header_list那条注释掉,不需要写入那么多次header。
id列表
我们使用一个csv文件,将需要搜索的id添加进去,然后读取该列表进行靶向搜索!

这样就可以了,我们需要得到球员的sofia网站上的id。这里我有通过名字搜索,通过ovr搜索,和通过俱乐部搜索,分别放在下面。
通过球员名字搜索
我们在这个网站上,通过名字搜索,会出现一个球员列表,例如搜索华伦天奴会出现以下球员:
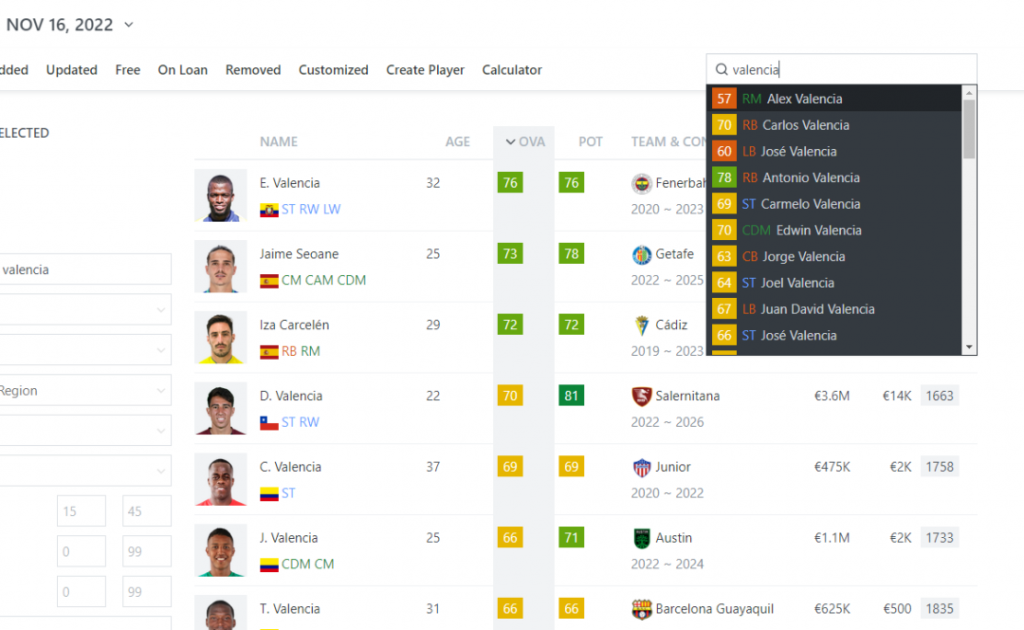
话不多说,直接上代码:

这个函数会获得所有搜索到的结果,没有的话会返回”not found”,需要注意的是会搜索到很多名字类似的球员,至于真正需要的是哪个,需要自己去过滤了。
同样的,把要搜索的名字放在一个csv里面,方便使用。

通过OVR搜索
搜索时通过球员的总属性值(OVR)来进行搜索。
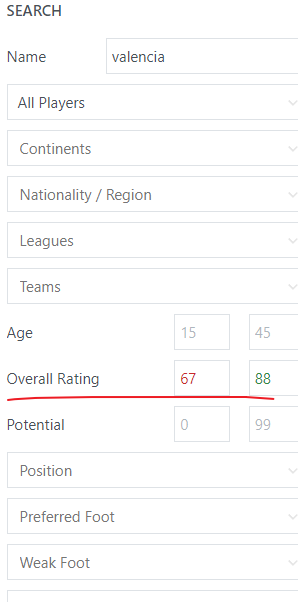
点击search后,发现网址变成了这样,可见oal就是overall low,oah是overall high的意思。

代码如下:


通过球队来搜索
球队搜索的话,需要知道club的id,我们选择teams,可以看到它唯一的club id和首发阵容。
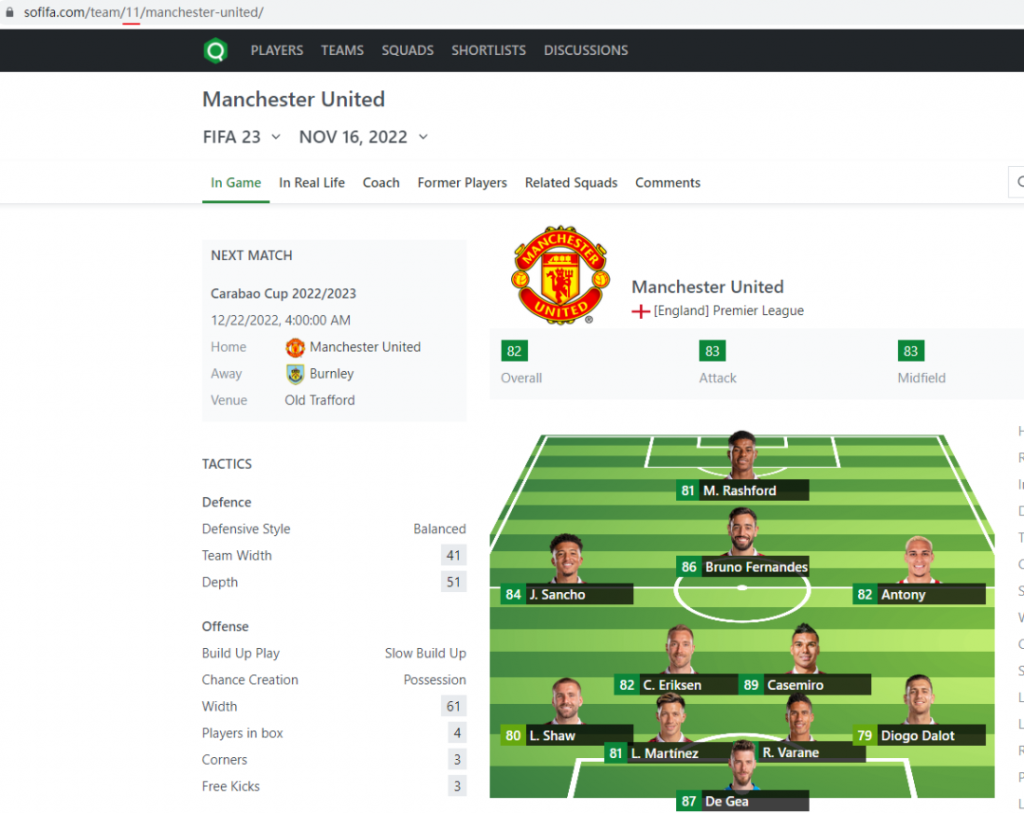
这里写下如何通过club id获得首发阵容:

总结
常言道,人生苦短,我用python。作为一个脚本语言,快和简单就是python最大的特点。大家可以根据自己的需求类定制这类爬虫,关于爬虫更高级的框架可以使用scappy等。对于常用的工具函数,比如写入csv,写入\读取excel等,可以按照自己的需求写在一个misc.py里面。实际上,因为经常有新的需求,所以写得很随便,,注释很多都没写。这种力大砖飞得写法是没有任何美感可言的,新的需求接踵而来,又没有时间去重构,能运行起来就谢天谢地了,看到运行完成的这句后 exited with in seconds后,就再也不想打开了。希望大家以此为戒,能够写出通俗易懂的代码。

本文首发于我们的公众号:世界杯到了,写个爬虫获取球员数据吧
文中的代码片段可以查看原文获取哦。